17 Simple Linear Regression
Situation:
- Metric response
- Matric predictor
17.1 The deluxe basic model
17.1.1 Likelihood
\[\begin{align*} y_{i} &\sim {\sf Norm}(\mu_i, \sigma) \\ \mu_i &\sim \beta_0 + \beta_1 x_i \end{align*}\]
Some variations:
- Replace normal distribution with something else (t is common).
- Allow standard deviations to vary with \(x\) as well as the mean.
- Use a different functional relationship between explanatory and response (non-linear regression)
Each of these is relatively easy to do. The first variation is sometimes called robust regression becuase it is more robust to unusual observations. Since it is no harder to work with t distributions than with normal distributions, that will become our go-to simple linear regression model.
\[\begin{align*} y_{i} &\sim {\sf T}(\mu_i, \sigma, \nu) \\ \mu_i &\sim \beta_0 + \beta_1 x_i \end{align*}\]
17.1.2 Priors
We need priors for \(\beta_0\), \(\beta_1\), \(\sigma\), and \(\nu\).
\(\nu\): We’ve already seend that a shifted Gamma with mean around 30 works well as a generic prior giving the data room to stear us away from normality if warranted.
\(\beta_1\): The MLE for \(\beta_1\) is
\[ \hat\beta_1 = r \frac{SD_y}{SD_x}\] so it makes sense to have a prior broadly covers the interval \((- \frac{SD_y}{SD_x}, \frac{SD_y}{SD_x})\).
\(\beta_0\): The MLE for \(\beta_0\) is
\[ \hat\beta_0 \; = \; \overline{y} - \hat \beta_1 \overline{x} \; = \; \overline{y} - r \frac{SD_y}{SD_x} \cdot \overline{x}\]
so we can pick a prior that broadly covers the interval \((\overline{y} - \frac{SD_y}{SD_x} \cdot \overline{x}, \overline{y} - \frac{SD_y}{SD_x} \cdot \overline{x})\)
\(\sigma\) measures the amount of variability in responses for a fixed value of \(x\) (and is assumed to be the same for each \(x\) in the simple version of the model). A weakly informative prior should cover the range of reasonable values of \(\sigma\) with plenty of room to spare. (Our 2-or-3-orders-of-magnititude-either-way uniform distribution might be a reasonable starting point.)
Here’s the big picture:
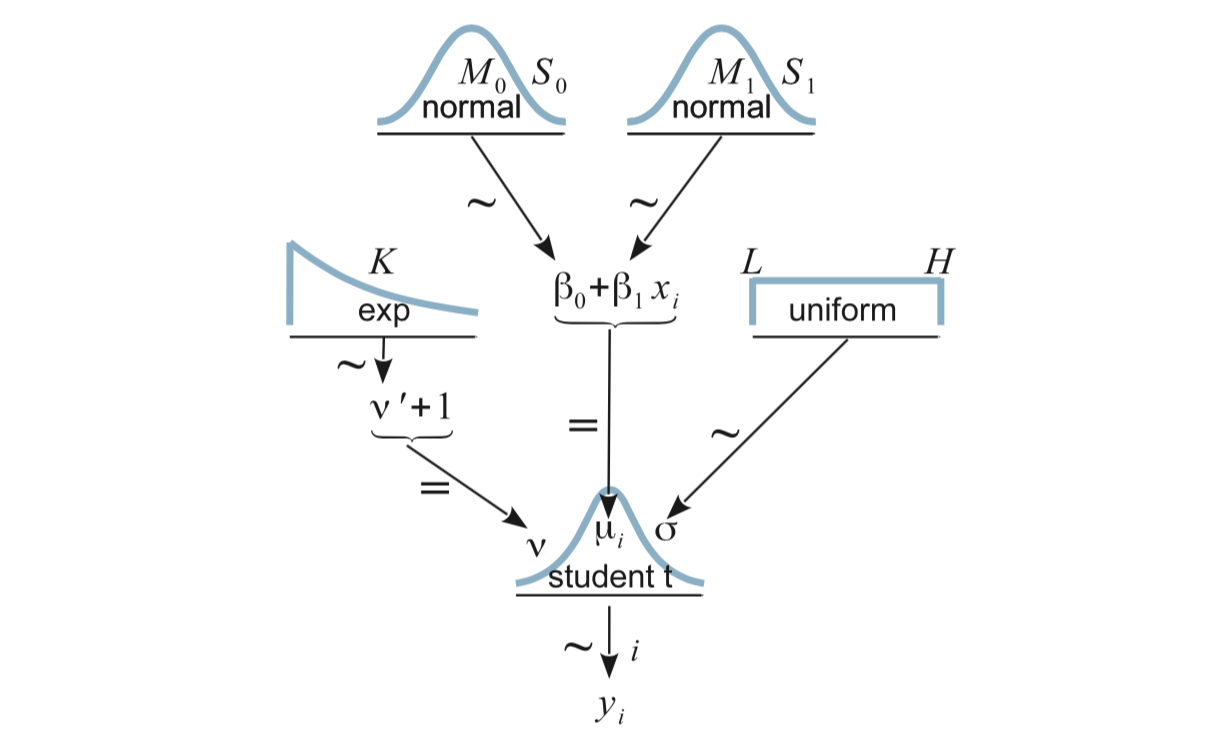
17.2 Example: Galton’s Data
Since we are looking at regression, let’s use an historical data set that was part of the origins of the regression story: Galton’s data on height. Galton collected data on the heights of adults and their parents.
head(mosaicData::Galton)| family | father | mother | sex | height | nkids |
|---|---|---|---|---|---|
| 1 | 78.5 | 67.0 | M | 73.2 | 4 |
| 1 | 78.5 | 67.0 | F | 69.2 | 4 |
| 1 | 78.5 | 67.0 | F | 69.0 | 4 |
| 1 | 78.5 | 67.0 | F | 69.0 | 4 |
| 2 | 75.5 | 66.5 | M | 73.5 | 4 |
| 2 | 75.5 | 66.5 | M | 72.5 | 4 |
To keep things simpler for the moment, let’s consider only women, and only one sibling per family.
set.seed(54321)
library(dplyr)
GaltonW <-
mosaicData::Galton %>%
filter(sex == "F") %>%
group_by(family) %>%
sample_n(1)Galton was interested in how people’s heights are related to their parents’ heights. He compbined the parents’ heights into the “mid-parent height”, which was the average of the two.
GaltonW <-
GaltonW %>%
mutate(midparent = (father + mother) / 2)
gf_point(height ~ midparent, data = GaltonW, alpha = 0.5)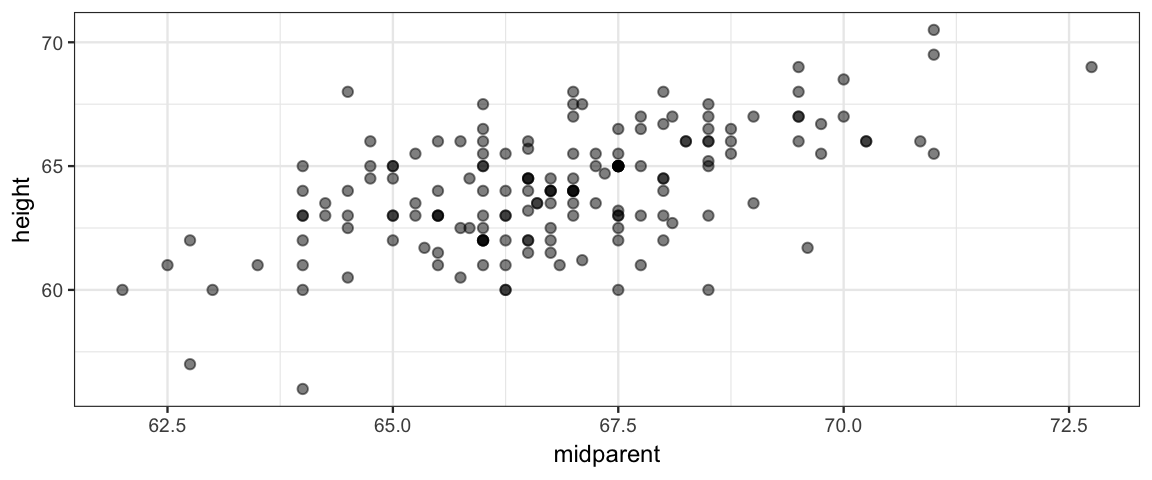
17.2.1 Describing the model to JAGS
galton_model <- function() {
for (i in 1:length(y)) {
y[i] ~ dt(mu[i], 1/sigma^2, nu)
mu[i] <- beta0 + beta1 * x[i]
}
sigma ~ dunif(6/100, 6 * 100)
nuMinusOne ~ dexp(1/29)
nu <- nuMinusOne + 1
beta0 ~ dnorm(0, 1/100^2) # 100 is order of magnitude of data
beta1 ~ dnorm(0, 1/4^2) # expect roughly 1-1 slope
}library(R2jags)
library(mosaic)
galton_jags <-
jags(
model = galton_model,
data = list(y = GaltonW$height, x = GaltonW$midparent),
parameters.to.save = c("beta0", "beta1", "sigma", "nu"),
n.iter = 5000,
n.burnin = 2000,
n.chains = 4,
n.thin = 1
)library(bayesplot)
library(CalvinBayes)
summary(galton_jags)## fit using jags
## 4 chains, each with 5000 iterations (first 2000 discarded)
## n.sims = 12000 iterations saved
## mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff
## beta0 10.695 8.008 -4.072 5.664 11.532 17.189 24.534 4.376 4
## beta1 0.800 0.120 0.593 0.702 0.787 0.877 1.020 4.071 4
## nu 33.016 27.311 6.134 14.178 24.807 42.854 106.351 1.002 1600
## sigma 1.849 0.130 1.594 1.761 1.849 1.935 2.102 1.020 140
## deviance 699.315 4.276 694.765 696.069 697.727 701.525 709.475 2.312 6
##
## DIC info (using the rule, pD = var(deviance)/2)
## pD = 3.3 and DIC = 702.6mcmc_combo(as.mcmc(galton_jags))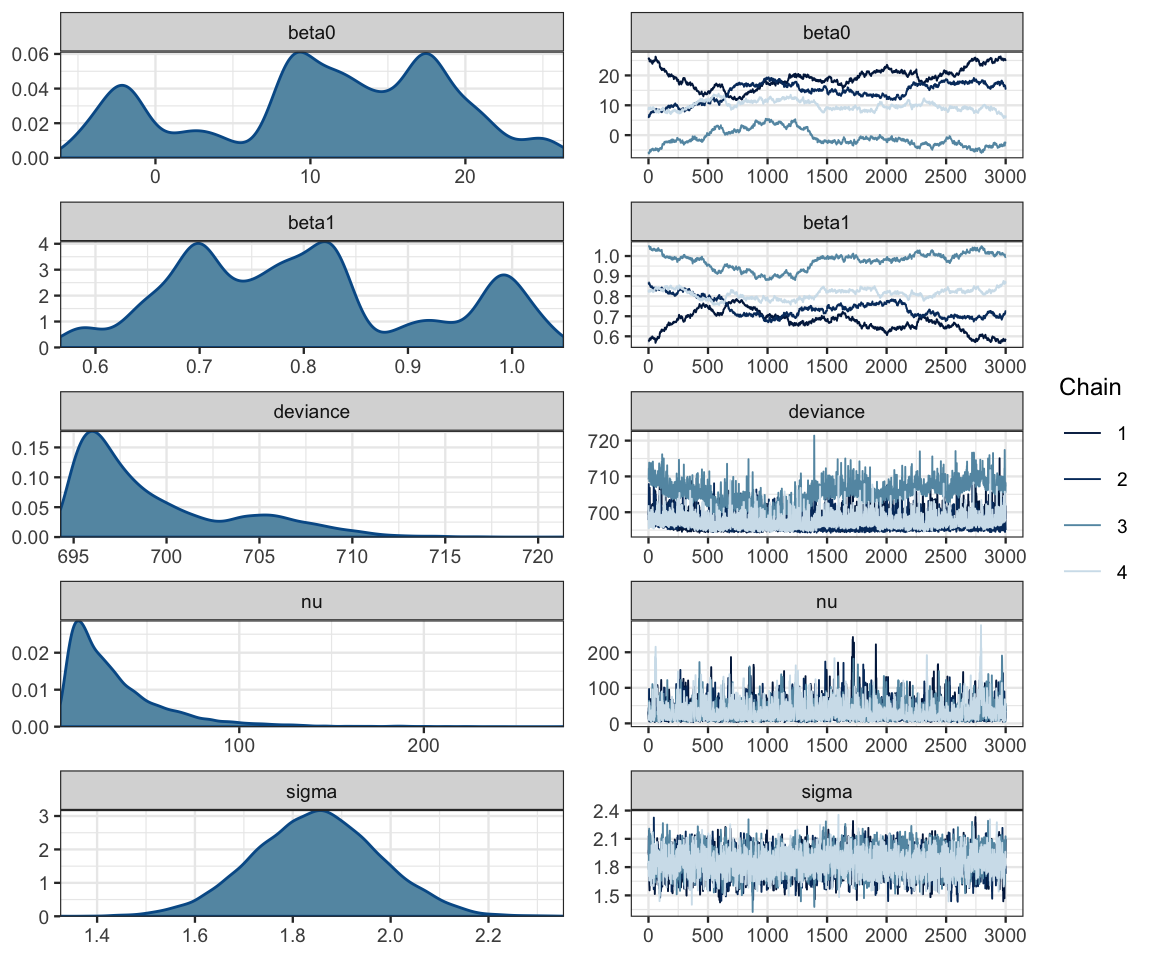
17.2.2 Problems and how to fix them
Clearly something is not working the way we would like with this model! Here’s a clue as to the problem:
posterior(galton_jags) %>%
gf_point(beta0 ~ beta1, color = ~ chain, alpha = 0.2, size = 0.4) %>%
gf_density2d(alpha = 0.5)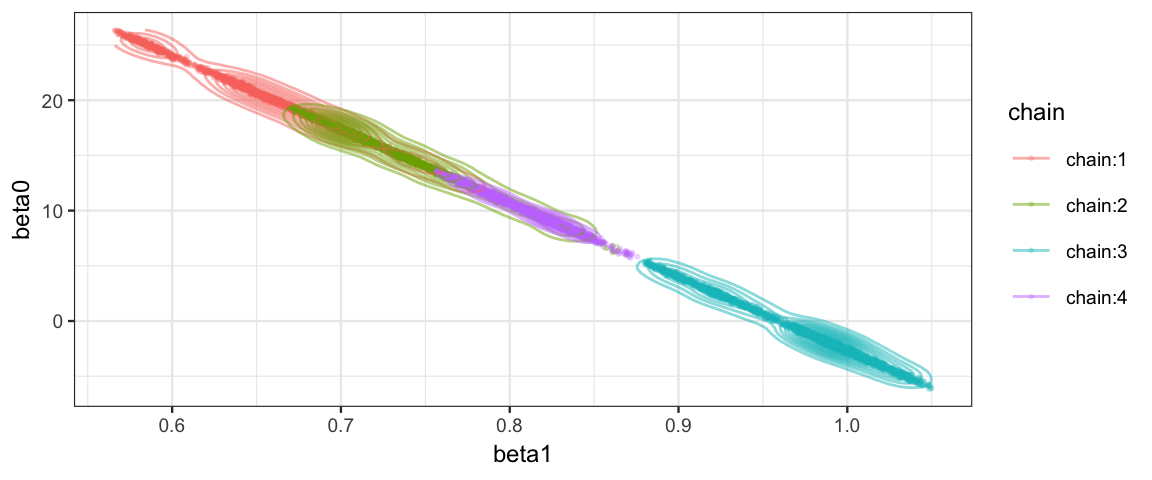
posterior(galton_jags) %>% filter(iter <= 250, chain == "chain:1") %>%
gf_step(beta0 ~ beta1, alpha = 0.8, color = ~iter) %>%
gf_density2d(alpha = 0.2) %>%
gf_refine(scale_color_viridis_c()) %>%
gf_facet_wrap(~chain) #, scales = "free")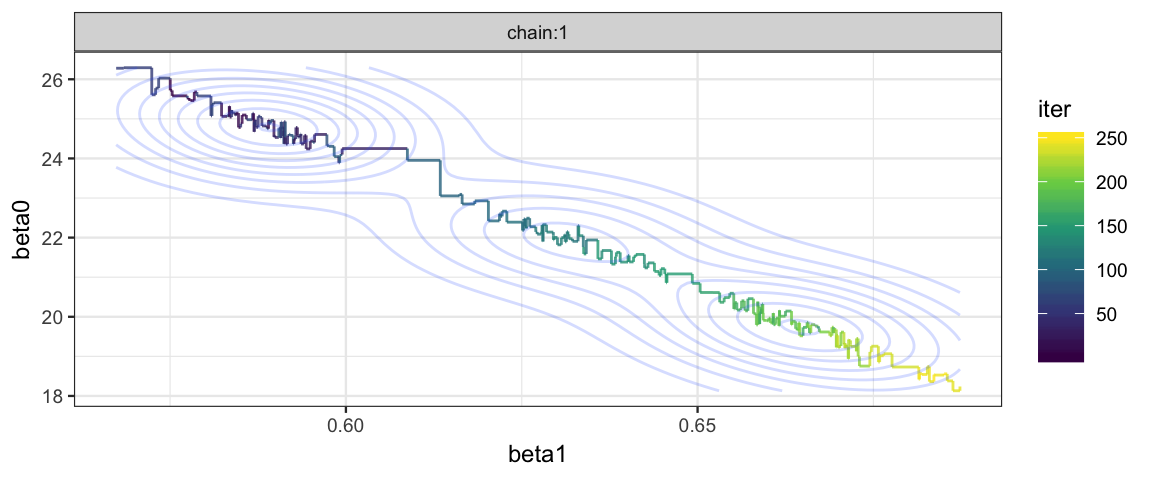
The correlation of the parameters in the posterior distribution produces a long, narrow, diagonal ridge that the Gibbs sampler samples only very slowly because it keeps bumping into edge of the cliff. (Remember, the Gibbs sampler only moves in “primary” directions.)
So how do we fix this? This is supposed to be the simple linear model after all. There are two ways we could hope to fix our problem.
Reparameterize the model so that the correlation between parameters (in the posterior distribution) is reduced or eliminated.
Use a different algorithm for posterior sampling. The problem is not with our model per se, rather it is with the method we are using (Gibbs) to sample from the posterior. Perhaps another algorithm will work better.
17.3 Centering and Standardizing
Reparameterization 1: centering
We can express this model as
\[\begin{align*} y_{i} &\sim {\sf T}(\mu_i, \sigma, \nu) \\ \mu_i &= \alpha_0 + \alpha_1 (x_i - \overline{x}) \end{align*}\]
Since
\[\begin{align*} \alpha_0 + \alpha_1 (x_i - \overline{x}) &= (\alpha_0 - \alpha_1 \overline{x}) + \alpha_1 x_i \end{align*}\]
We see that \(\beta_0 = \alpha_0 - \alpha_1 \overline{x}\) and \(\beta_1 = \alpha_1\). So we can easily recover the original parameters if we like. (And if we are primarily interested in \(\beta_1\), no translation is required.)
This reparameterization maintains the natural scale of the data, and both \(\alpha_0\) and \(\alpha_1\) are easily interpreted: \(\alpha_0\) is the mean response when the predictor is the average of the predictor values in the data.
Reparameterization 2: standardization
We can also express our model as
\[\begin{align*} z_{y_{i}} &\sim {\sf T}(\mu_i, \sigma, \nu) \\[3mm] \mu_i &= \alpha_0 + \alpha_1 z_{x_i} \\[5mm] z_{x_i} &= \frac{x_i - \overline{x}}{SD_x} \\[3mm] z_{y_i} &= \frac{y_i - \overline{y}}{SD_y} \\[3mm] \end{align*}\]
Here the change in the model is due to a transformation of the data. Subtracting the mean and dividing by the standard deviation is called standardization, and the values produced are sometimes called z-scores. The resulting distributions of \(zy\) and \(zx\) will have mean 0 and standard deviation 1. So in addition to breaking the correlation pattern, we have now put things on a standard scale, regardless of what the original units were. This can be useful for picking constants in priors (we won’t have to estimate the scale of the data involved). In addition, some algorithms work better if all the variables involved have roughly the same scale.
The downside is that we usually need to convert back to the original scales of \(x\) and \(y\) in order to interpret the results. But this is only a matter of a little easy algebra:
\[\begin{align*} \hat{z}_{y_i} &= \alpha_0 + \alpha_1 z{x_i} \\ \frac{\hat{y}_i - \overline{y}}{SD_y} &= \alpha_0 + \alpha_1 \frac{x_i - \overline{x}}{SD_x} \\ \hat{y}_i &= \overline{y} + \alpha_0 SD_y + \alpha_1 SD_y \frac{x_i - \overline{x}}{SD_x} \\ \hat{y}_i &= \underbrace{\left[\overline{y} + \alpha_0 SD_y - \alpha_1\frac{SD_y}{SD_x} \overline{x} \right]}_{\beta_0} + \underbrace{\left[\alpha_1 \frac{SD_y}{SD_x}\right]}_{\beta_1} x_i \end{align*}\]
Since Kruscske demonstrates standardization, we’ll do centering here.
galtonC_model <- function() {
for (i in 1:length(y)) {
y[i] ~ dt(mu[i], 1/sigma^2, nu)
mu[i] <- alpha0 + alpha1 * (x[i] - mean(x))
}
sigma ~ dunif(6/100, 6 * 100)
nuMinusOne ~ dexp(1/29)
nu <- nuMinusOne + 1
alpha0 ~ dnorm(0, 1/100^2) # 100 is order of magnitude of data
alpha1 ~ dnorm(0, 1/4^2) # expect roughly 1-1 slope
beta0 = alpha0 - alpha1 * mean(x)
beta1 = alpha1 # not necessary, but gives us both names
}
galtonC_jags <-
jags(
model = galtonC_model,
data = list(y = GaltonW$height, x = GaltonW$midparent),
parameters.to.save = c("beta0", "beta1", "alpha0", "alpha1", "sigma", "nu"),
n.iter = 5000,
n.burnin = 2000,
n.chains = 4,
n.thin = 1
)summary(galtonC_jags)## fit using jags
## 4 chains, each with 5000 iterations (first 2000 discarded)
## n.sims = 12000 iterations saved
## mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff
## alpha0 64.105 0.149 63.812 64.004 64.106 64.208 64.390 1.001 12000
## alpha1 0.740 0.081 0.577 0.687 0.740 0.795 0.900 1.001 12000
## beta0 14.686 5.428 4.008 11.050 14.655 18.253 25.540 1.001 12000
## beta1 0.740 0.081 0.577 0.687 0.740 0.795 0.900 1.001 12000
## nu 32.250 24.769 6.281 14.368 24.592 42.701 98.596 1.001 8600
## sigma 1.841 0.128 1.585 1.757 1.842 1.926 2.091 1.001 5300
## deviance 697.587 2.496 694.651 695.740 696.961 698.787 704.017 1.001 12000
##
## DIC info (using the rule, pD = var(deviance)/2)
## pD = 3.1 and DIC = 700.7mcmc_combo(as.mcmc(galtonC_jags))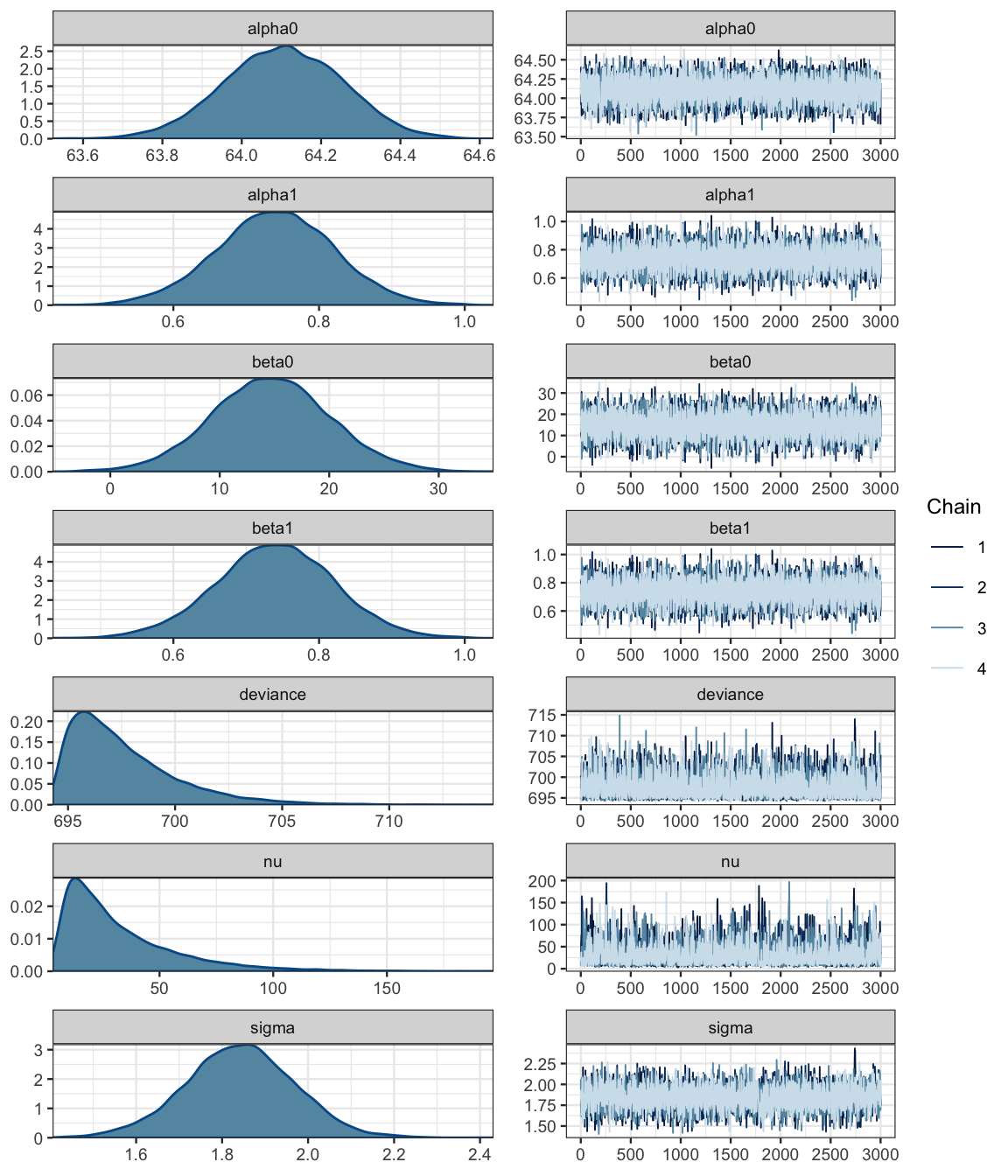
Ah! That looks much better than before.
17.3.1 \(\beta_0\) and \(\beta_1\) are still correlated
Reparameterization has not changed our model, only the way it is described. In particular, \(\beta_0\) and \(\beta_1\) remain correlated in the posterior. But \(\alpha_0\) and \(\alpha_1\) are not correlated, and these are the parameters JAGS is using to sample.
gf_point(beta1 ~ beta0, data = posterior(galtonC_jags), alpha = 0.1)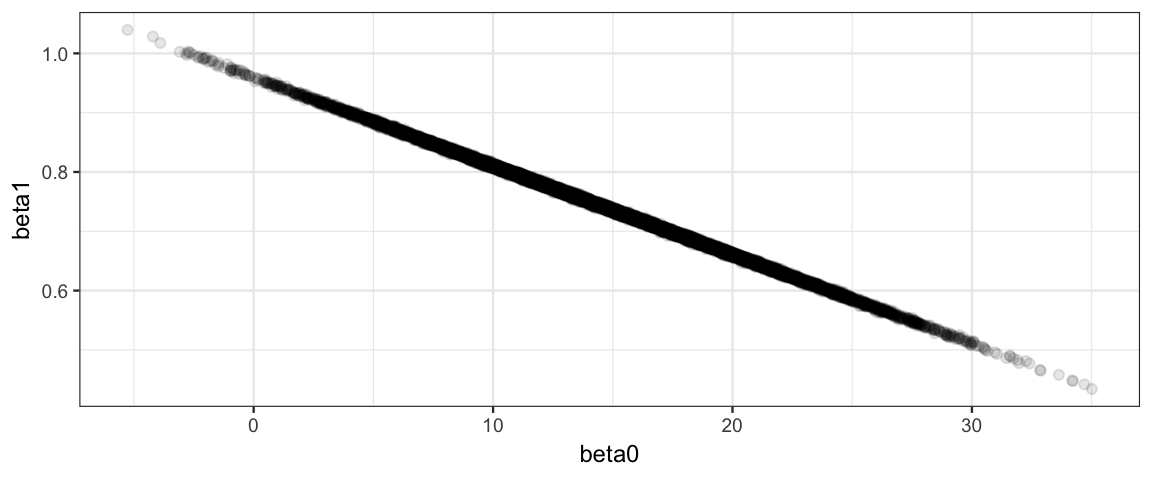
gf_point(alpha1 ~ alpha0, data = posterior(galtonC_jags), alpha = 0.1)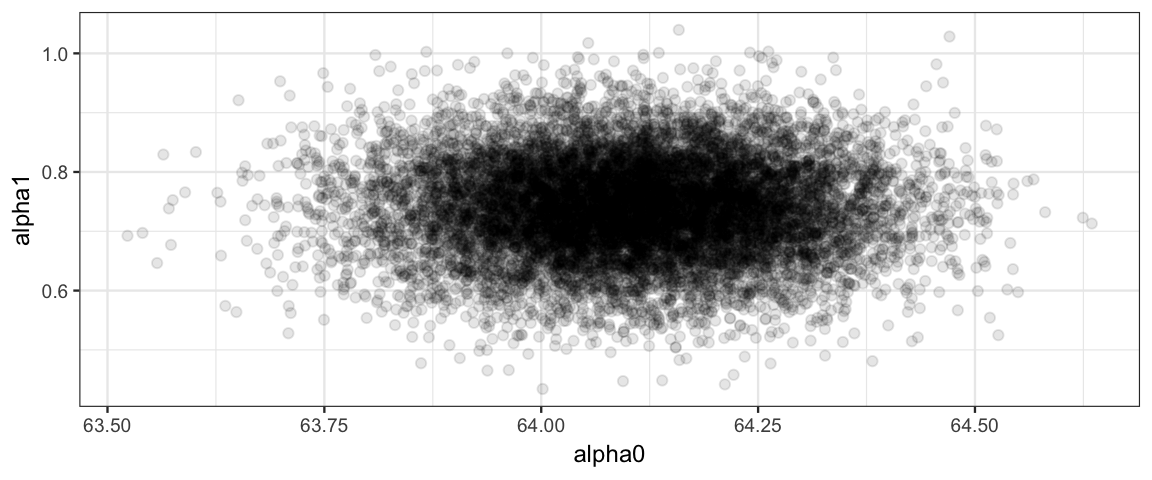
17.4 We’ve fit a model, now what?
After centering or standardizing, JAGS works much better. We can now sample from our posterior distribution. But what do we do with our posterior samples?
17.4.1 Estimate parameters
If we are primarily interested in a regression parameter (usually the slope parameter is much more interesting than the intercept parameter), we can use an HDI to express our estimate.
hdi(posterior(galtonC_jags), pars = "beta1")| par | lo | hi | mode | prob |
|---|---|---|---|---|
| beta1 | 0.5825 | 0.9044 | 0.7278 | 0.95 |
mcmc_areas(as.mcmc(galtonC_jags), pars = "beta1", prob = 0.95)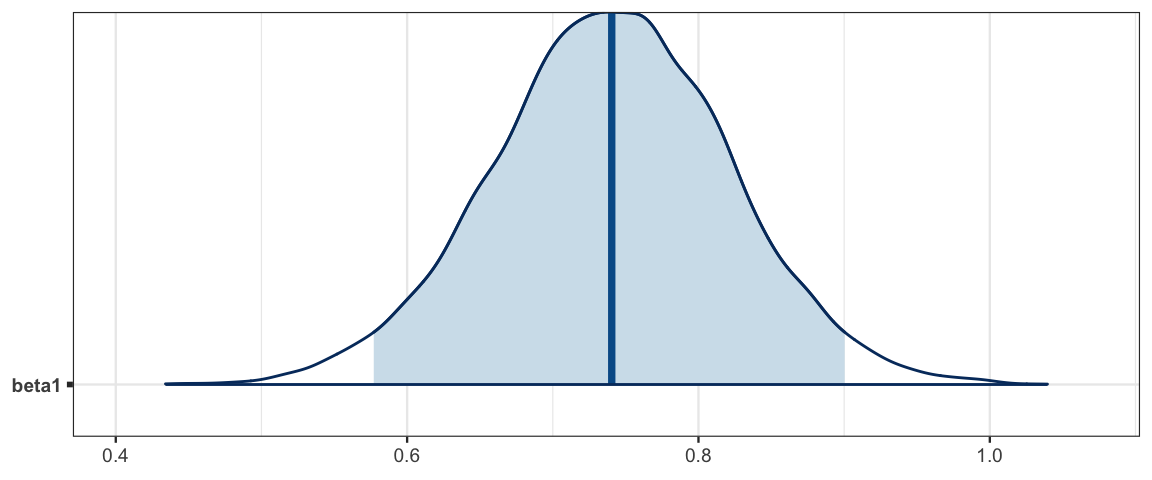
Galton noticed what we see here: that the slope is less than 1. This means that children of taller than average parents tend to be shorter than their parents and children of below average parents tend to be taller than their parents. He referred to this in his paper as “regression towards mediocrity”. As it turns out, this was not a special feature of the heridity of heights but a general feature of linear models. Find out more in this Wikipedia artilce.
17.4.2 Make predictions
Suppse we know the heights of a father and mother, from which we compute
ther mid-parent height \(x\).
How tall would we predict their daughters will be as adults?
Each posterior sample provides an answer
by describing a t distribution with nu degrees of freedom,
mean \(\beta_0 + \beta_1 x\), and standard deviation \(\sigma\).
The posterior distribution of the average hieght of daughters born to parents with midparent height \(x = 70\) is shown below, along with an HDI.
posterior(galtonC_jags) %>%
mutate(mean_daughter = beta0 + beta1 * 70) %>%
gf_dens(~mean_daughter)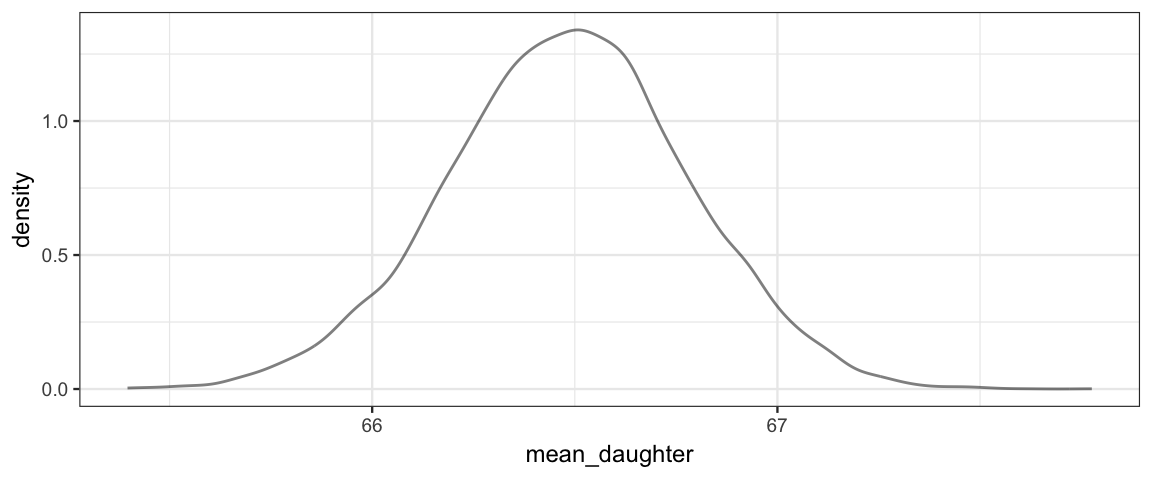
Galton_hdi <-
posterior(galtonC_jags) %>%
mutate(mean_daughter = beta0 + beta1 * 70) %>%
hdi(pars = "mean_daughter")
Galton_hdi| par | lo | hi | mode | prob |
|---|---|---|---|---|
| mean_daughter | 65.89 | 67.07 | 66.5 | 0.95 |
So on average, we would predict the daughters to be about 66 or 67 inches tall.
We can visualize this by drawing a line for each posterior sample. The HDI should span the middle 95% of these.
gf_abline(intercept = ~beta0, slope = ~beta1, alpha = 0.01,
color = "steelblue",
data = posterior(galtonC_jags) %>% sample_n(2000)) %>%
gf_point(height ~ midparent, data = GaltonW,
inherit = FALSE, alpha = 0.5) %>%
gf_errorbar(lo + hi ~ 70, data = Galton_hdi, color = "skyblue",
width = 0.2, size = 1.2, inherit = FALSE)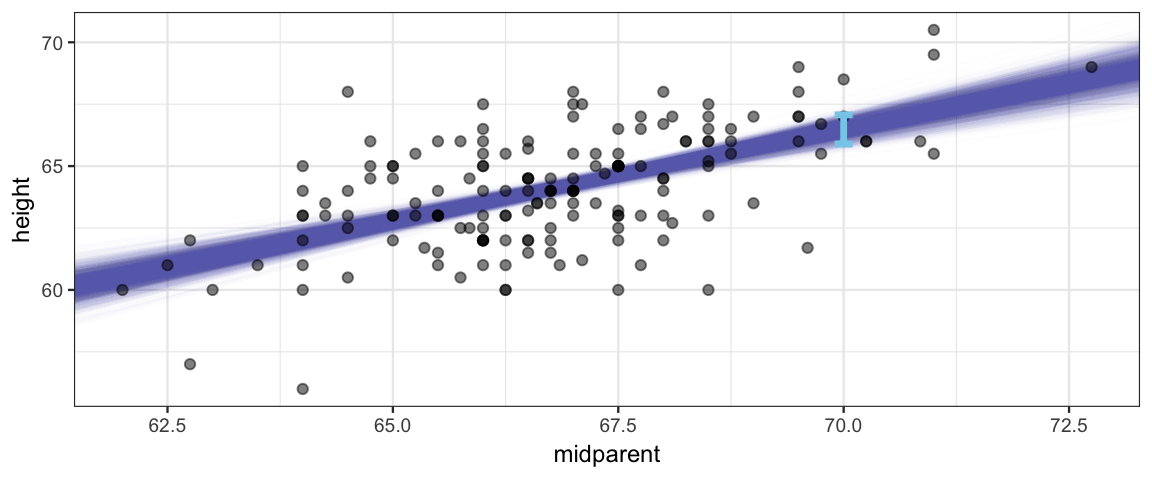
But this may not be the sort of prediction we want. Notice that most daughters’ heights are not in the blue band in the picture. That band tells about the mean but doesn’t take into account how much individuals vary about that mean. We can add that information in by taking our estimate for \(\sigma\) into account.
Here we generate heights by adding noise to the estimate given by values of \(\beta_0\) and \(\beta_1\).
posterior(galtonC_jags) %>%
mutate(new_ht = beta0 + beta1 * 70 + rt(1200, df = nu) * sigma) %>%
gf_point(new_ht ~ 70, alpha = 0.01, size = 0.7, color = "steelblue") %>%
gf_point(height ~ midparent, data = GaltonW,
inherit = FALSE, alpha = 0.5) 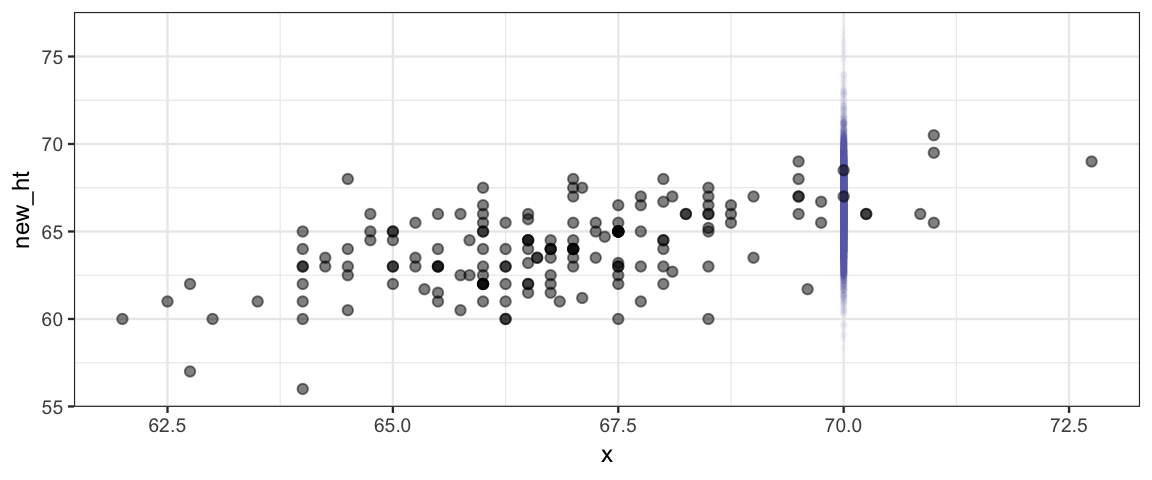
Galton_hdi2 <-
posterior(galtonC_jags) %>%
mutate(new_ht = beta0 + beta1 * 70 + rt(1200, df = nu) * sigma) %>%
hdi(regex_pars = "new")
Galton_hdi2| par | lo | hi | mode | prob |
|---|---|---|---|---|
| new_ht | 62.38 | 70.53 | 66.46 | 0.95 |
So our model expects that most daughters whose parents have a midparent height
of 70 inches are between
62.4 and
70.5
inches tall. Notice that this interval
is taking into account both the uncertainty in our estimates of the
parameters \(\beta_0\), \(\beta_1\), \(\sigma\), and \(\nu\) and the variability in
heights that \(\sigma\) and \(\nu\) indicate.
17.4.3 Posterior Predictive Checks
With a little more work, we can create intervals like this at several different midparent heights.
Post_galtonC <- posterior(galtonC_jags)
Grid <-
expand.grid(midparent = 60:75, iter = 1:nrow(Post_galtonC))
posterior(galtonC_jags) %>%
mutate(noise = rt(12000, df = nu) * sigma) %>%
left_join(Grid) %>%
mutate(height = beta0 + beta1 * midparent + noise) %>%
group_by(midparent) %>%
do(hdi(., pars = "height")) ## Joining, by = "iter"## # A tibble: 16 x 6
## # Groups: midparent [16]
## midparent par lo hi mode prob
## <int> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 60 height 55.2 63.2 58.6 0.95
## 2 61 height 55.9 63.9 59.3 0.95
## 3 62 height 56.7 64.6 60.4 0.95
## 4 63 height 57.4 65.3 61.4 0.95
## 5 64 height 58.3 66.1 61.8 0.95
## 6 65 height 59.1 66.8 62.4 0.95
## 7 66 height 59.7 67.4 62.9 0.95
## 8 67 height 60.5 68.2 64.6 0.95
## 9 68 height 61.2 69.0 65.0 0.95
## 10 69 height 61.9 69.6 66.1 0.95
## 11 70 height 62.6 70.4 66.6 0.95
## 12 71 height 63.1 70.9 67.9 0.95
## 13 72 height 63.9 71.8 68.2 0.95
## 14 73 height 64.7 72.5 69.1 0.95
## 15 74 height 65.4 73.3 68.7 0.95
## 16 75 height 66.0 74.1 69.7 0.95posterior(galtonC_jags) %>%
mutate(noise = rt(12000, df = nu) * sigma) %>%
left_join(Grid) %>%
mutate(avg_height = beta0 + beta1 * midparent,
height = avg_height + noise) %>%
group_by(midparent) %>%
do(hdi(., pars = "height")) %>%
gf_ribbon(lo + hi ~ midparent, fill = "steelblue", alpha = 0.2) %>%
gf_errorbar(lo + hi ~ midparent, width = 0.2, color = "steelblue", size = 1.2) %>%
gf_point(height ~ midparent, data = GaltonW,
inherit = FALSE, alpha = 0.5)## Joining, by = "iter"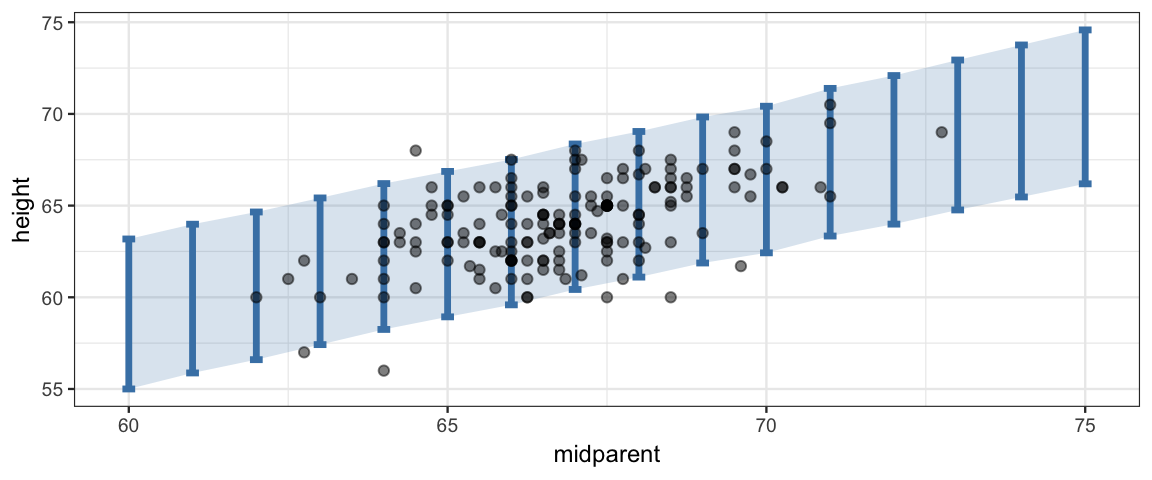
Comparing the data to the posterior predictions of the model is called a posterior predictive check; we are checking to see whether the data are consistent with what our posterior distribution would predict. In this case, things look good: most, but not all of the data is falling inside the band where our models predicts 95% of new observations would fall.
If the posterior predictive check indicates systematic problems with our model, it may lead us to propose another (we hope better) model.
17.4.4 Posterior predictive checks with bayesplot
It takes a bit of work to construct the data needed for the plot above. The bayesplot package provides a number of posterior predicitive check (ppc) plots. These functions require two important inputs:
y: a vector of response values – usually the values from the original data set.yrep: a matrix of simulatedyvalues. Each row corresponds to one posterior sample. There is one column for each value ofy.
So the rows of yrep can be compared with y to see if the model
is behaving well.
Side note: We can compute our simulated \(y\) values using predictor values that are just like in our data or using other predictor values of our choosing. The second options lets on consider counterfactual situations. To distinguish these, some people use \(y_rep\) for the former and \(\tilde{y}\) for the latter.
Now all the work is in creating the yrep matrix. To simplify that, we will use
CalvinBayes::posterior_calc(). We will do this two ways, once for average
values of height and once for individual values of height (taking into account the
variability from person to person as quantified by \(\nu\), and \(\sigma\).
y_avg <-
posterior_calc(
galtonC_jags,
height ~ beta0 + beta1 * midparent,
data = GaltonW)
y_ind <-
posterior_calc(
galtonC_jags,
height ~
beta0 + beta1 * midparent + rt(nrow(GaltonW), df = nu) * sigma,
data = GaltonW)The various posterior predictive check plots begin ppc_. Here is an example:
ppc_intervals(GaltonW$height, y_avg, x = GaltonW$midparent)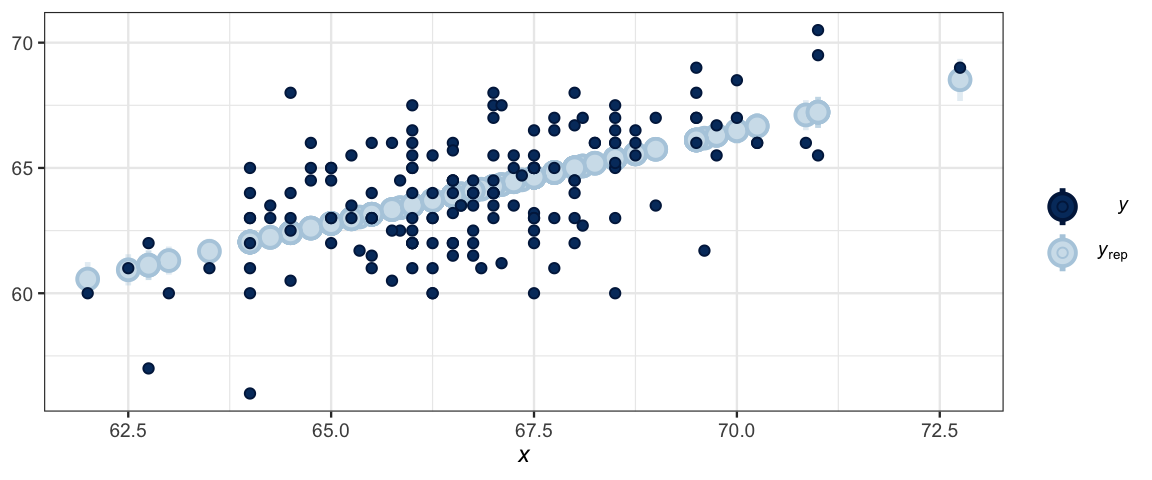
ppc_intervals(GaltonW$height, y_ind, x = GaltonW$midparent)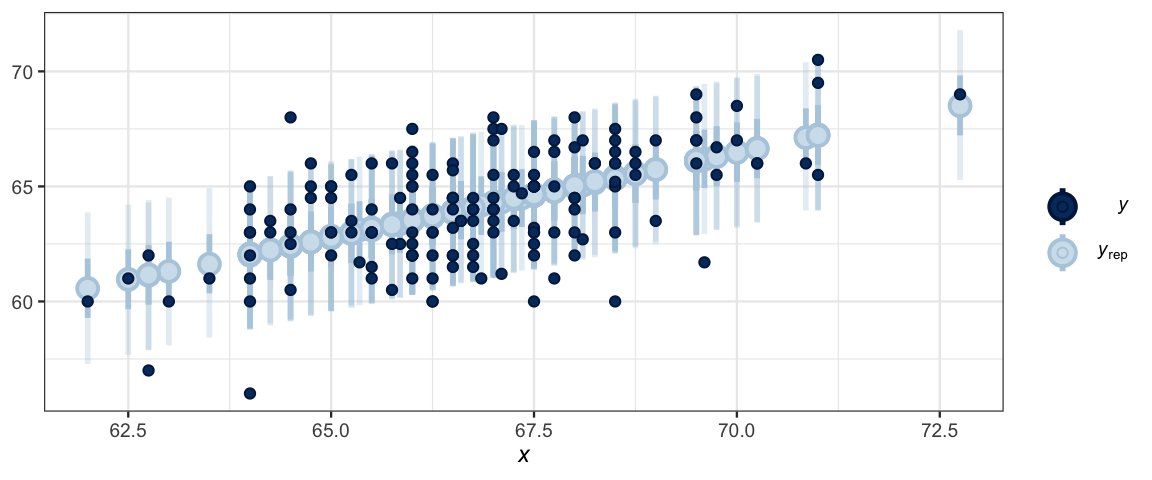
If we want a ribbon, like in our plot above, we can almost get it,
but ppc_ribbon() connects the dots in a way that isn’t useful for this
model.
ppc_ribbon(GaltonW$height, y_ind, x = GaltonW$midparent)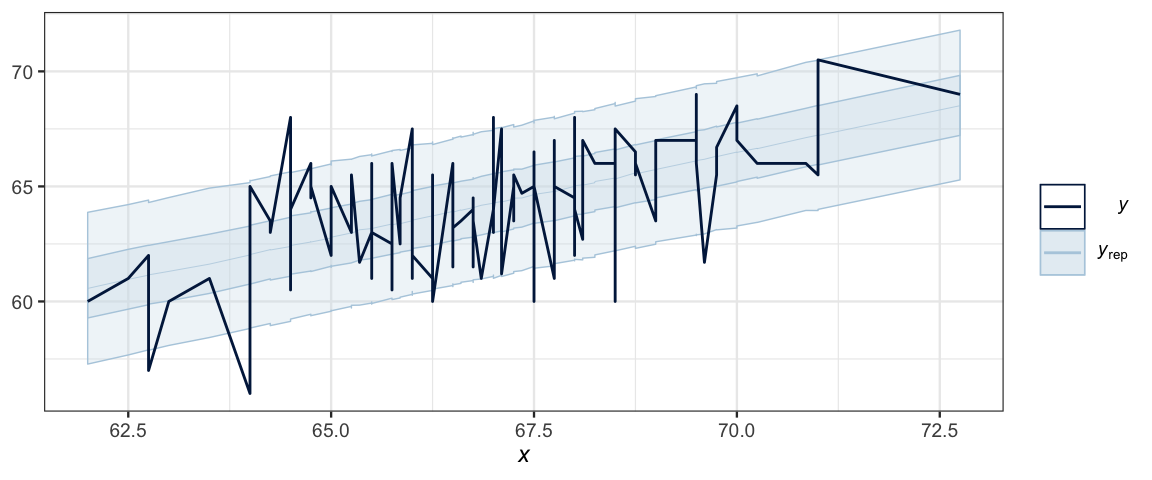
Fortunately, we can request the data used to create the plot and make our own plot however we like.
plot_data <-
ppc_ribbon_data(GaltonW$height, y_ind, x = GaltonW$midparent)
glimpse(plot_data)## Observations: 168
## Variables: 10
## $ y_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22…
## $ y_obs <dbl> 69.0, 65.5, 65.0, 61.0, 64.5, 63.0, 66.5, 65.5, 64.0, 64.5, 68.0, 63.5, 67.5,…
## $ x <dbl> 72.75, 69.75, 67.50, 67.75, 68.00, 67.75, 67.75, 67.50, 67.00, 67.00, 68.00, …
## $ outer_width <dbl> 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.…
## $ inner_width <dbl> 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.…
## $ ll <dbl> 65.28, 63.12, 61.52, 61.55, 61.79, 61.59, 61.71, 61.51, 61.09, 61.01, 61.84, …
## $ l <dbl> 67.22, 65.02, 63.41, 63.52, 63.72, 63.51, 63.57, 63.39, 63.01, 62.98, 63.74, …
## $ m <dbl> 68.51, 66.32, 64.64, 64.78, 65.01, 64.79, 64.85, 64.63, 64.27, 64.26, 65.03, …
## $ h <dbl> 69.83, 67.62, 65.91, 66.07, 66.24, 66.07, 66.08, 65.89, 65.55, 65.55, 66.28, …
## $ hh <dbl> 71.79, 69.48, 67.85, 68.01, 68.18, 68.03, 68.04, 67.76, 67.44, 67.44, 68.18, …plot_data %>%
gf_ribbon(ll + hh ~ x, fill = "steelblue") %>%
gf_ribbon(l + h ~ x, fill = "steelblue") %>%
gf_line(m ~ x, color = "steelblue") %>%
gf_point(y_obs ~ x, alpha = 0.5)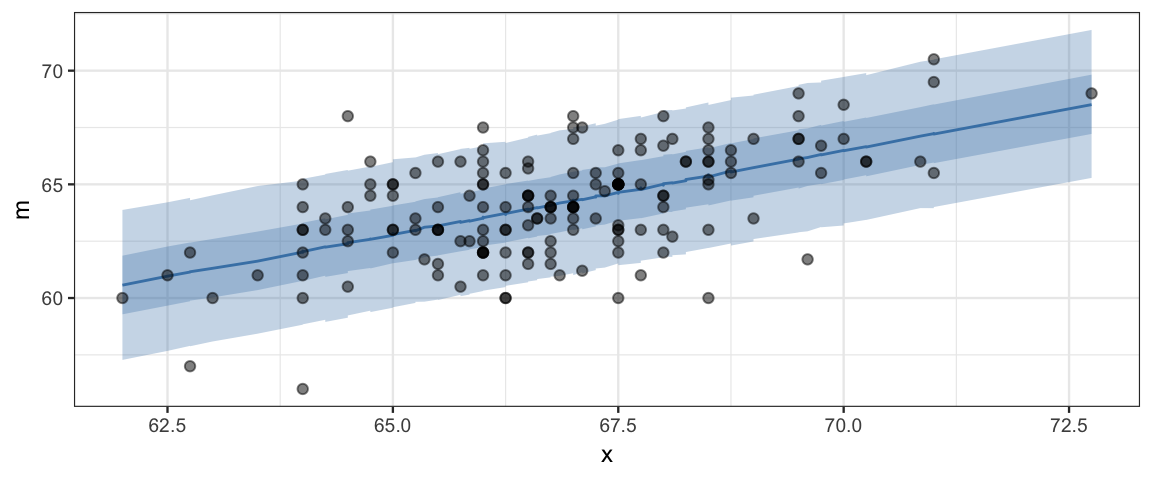
plot_data %>%
gf_smooth(ll ~ x, color = "steelblue") %>%
gf_smooth(hh ~ x, color= "steelblue") %>%
gf_smooth(m ~ x, color= "steelblue") %>%
gf_point(y_obs ~ x, alpha = 0.5)## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'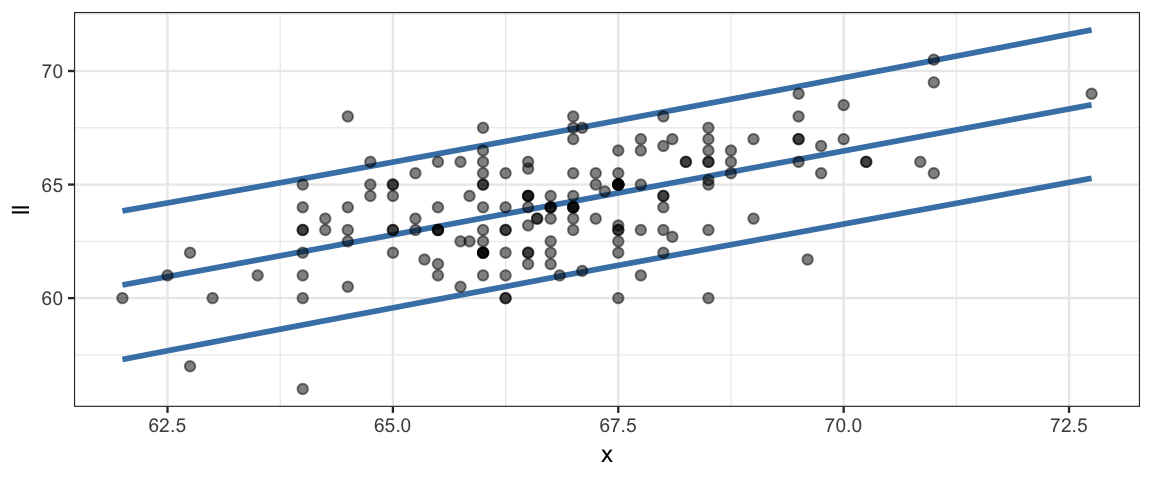
There are quite a number of these, but most only work for certain types of models.
apropos("^ppc_")## [1] "ppc_bars" "ppc_bars_grouped" "ppc_boxplot"
## [4] "ppc_data" "ppc_dens" "ppc_dens_overlay"
## [7] "ppc_ecdf_overlay" "ppc_error_binned" "ppc_error_hist"
## [10] "ppc_error_hist_grouped" "ppc_error_scatter" "ppc_error_scatter_avg"
## [13] "ppc_error_scatter_avg_vs_x" "ppc_freqpoly" "ppc_freqpoly_grouped"
## [16] "ppc_hist" "ppc_intervals" "ppc_intervals_data"
## [19] "ppc_intervals_grouped" "ppc_loo_intervals" "ppc_loo_pit"
## [22] "ppc_loo_pit_overlay" "ppc_loo_pit_qq" "ppc_loo_ribbon"
## [25] "ppc_ribbon" "ppc_ribbon_data" "ppc_ribbon_grouped"
## [28] "ppc_rootogram" "ppc_scatter" "ppc_scatter_avg"
## [31] "ppc_scatter_avg_grouped" "ppc_stat" "ppc_stat_2d"
## [34] "ppc_stat_freqpoly_grouped" "ppc_stat_grouped" "ppc_violin_grouped"17.4.5 PPC with custom data
We are not required to use the original data, we can make other data anyway we like.
Since the only value from the data that we used was midparent, we can simply create
a data frame with the midparent values that interest us. We might do this to
see what the model things about some counterfactual situation or simply to have a
less cluttered plot. Unfortunately, the ppc_ functions require y-values. We can
trick them by supplying Inf. (NA does not work.)
NewData <-
tibble(
midparent = seq(60, 75, by = 1),
height = Inf
)
y_avg2 <-
posterior_calc(
galtonC_jags,
height ~ beta0 + beta1 * midparent,
data = NewData)
y_ind2 <-
posterior_calc(
galtonC_jags,
height ~
beta0 + beta1 * midparent + rt(1, df = nu) * sigma,
data = NewData)ppc_intervals(NewData$height, y_avg2, x = NewData$midparent) %>%
gf_point(height ~ midparent, data = GaltonW, inherit = FALSE) 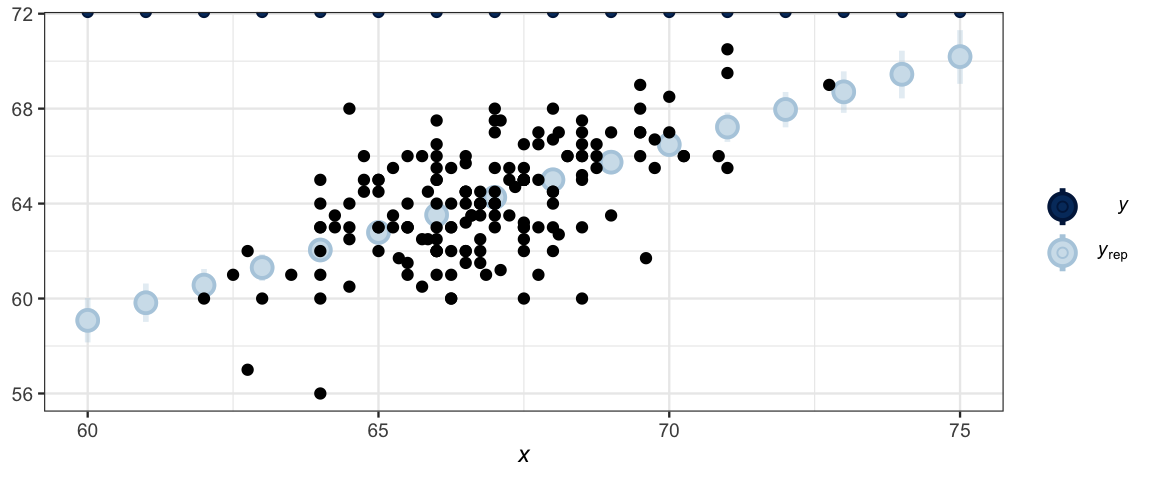
ppc_intervals(NewData$height, y_ind2, x = NewData$midparent) %>%
gf_point(height ~ midparent, data = GaltonW, inherit = FALSE) 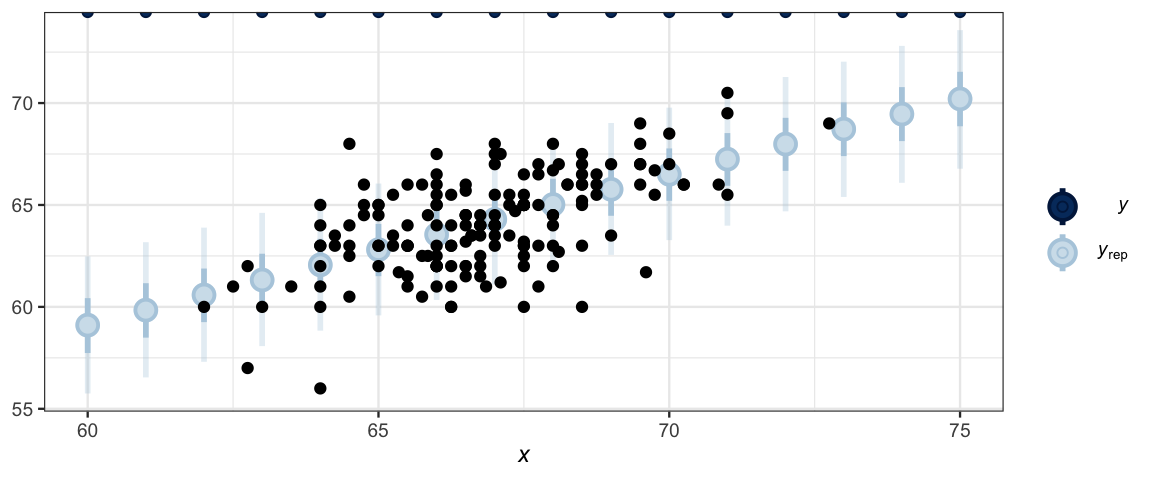
ppc_ribbon(NewData$height, y_ind2, x = NewData$midparent) %>%
gf_point(height ~ midparent, data = GaltonW, inherit = FALSE) 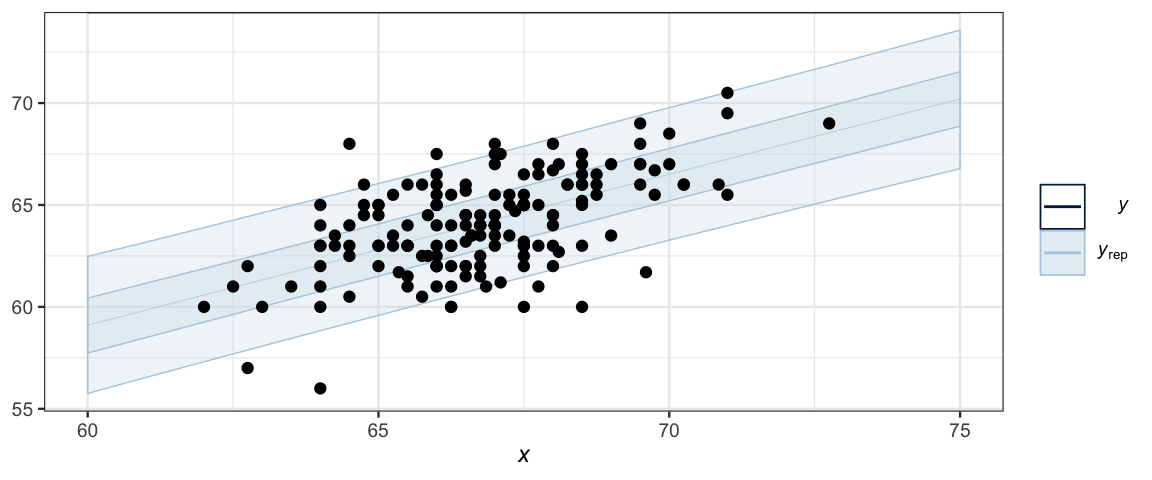
17.5 Fitting models with Stan
Centering (or standardizing) is sufficient to make JAGS efficient enough to use. But we can also use Stan, and since Stan is not bothered by correlation in the posterior the way JAGS is, Stan works well even without reparamterizing the model.
Here is the Stan equivalent to our original JAGS model.
data {
int<lower=0> N; // N is a non-negative integer
vector[N] y; // y is a length-N vector of reals
vector[N] x; // x is a length-N vector of reals
}
parameters {
real beta0;
real beta1;
real<lower=0> sigma;
real<lower=0> nuMinusOne;
}
transformed parameters{
real<lower=0> nu;
nu = nuMinusOne + 1;
}
model {
// we could use a for loop like this:
// for (i in 1:N) {
// y[i] ~ student_t(nu, beta0 + beta1 * x[i], sigma);
//}
// but vectorization makes things terser:
y ~ student_t(nu, beta0 + beta1 * x, sigma);
beta0 ~ normal(0, 100);
beta1 ~ normal(0, 4);
sigma ~ uniform(6.0 / 100.0, 6.0 * 100.0);
nuMinusOne ~ exponential(1/29.0);
}library(rstan)
galton_stanfit <-
sampling(
galton_stan,
data = list(
N = nrow(GaltonW),
x = GaltonW$midparent,
y = GaltonW$height
),
chains = 4,
iter = 2000,
warmup = 1000
) Note that the slope and intercept parameters remain correlated in the posterior, but this doesn’t bother Stan the way it bothers JAGS.
galton_stanfit## Inference for Stan model: 210145742d5cefe996c77a84ec632eb5.
## 4 chains, each with iter=2000; warmup=1000; thin=1;
## post-warmup draws per chain=1000, total post-warmup draws=4000.
##
## mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
## beta0 14.67 0.15 5.38 3.96 11.06 14.68 18.13 25.29 1312 1
## beta1 0.74 0.00 0.08 0.58 0.69 0.74 0.79 0.90 1305 1
## sigma 1.84 0.00 0.13 1.59 1.75 1.84 1.92 2.09 1611 1
## nuMinusOne 32.15 0.72 27.52 5.28 13.47 23.59 41.91 105.11 1460 1
## nu 33.15 0.72 27.52 6.28 14.47 24.59 42.91 106.11 1460 1
## lp__ -250.00 0.04 1.40 -253.72 -250.68 -249.66 -248.99 -248.32 1420 1
##
## Samples were drawn using NUTS(diag_e) at Fri May 10 21:27:46 2019.
## For each parameter, n_eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor on split chains (at
## convergence, Rhat=1).gf_point(beta1 ~ beta0, data = posterior(galton_stanfit), alpha = 0.5)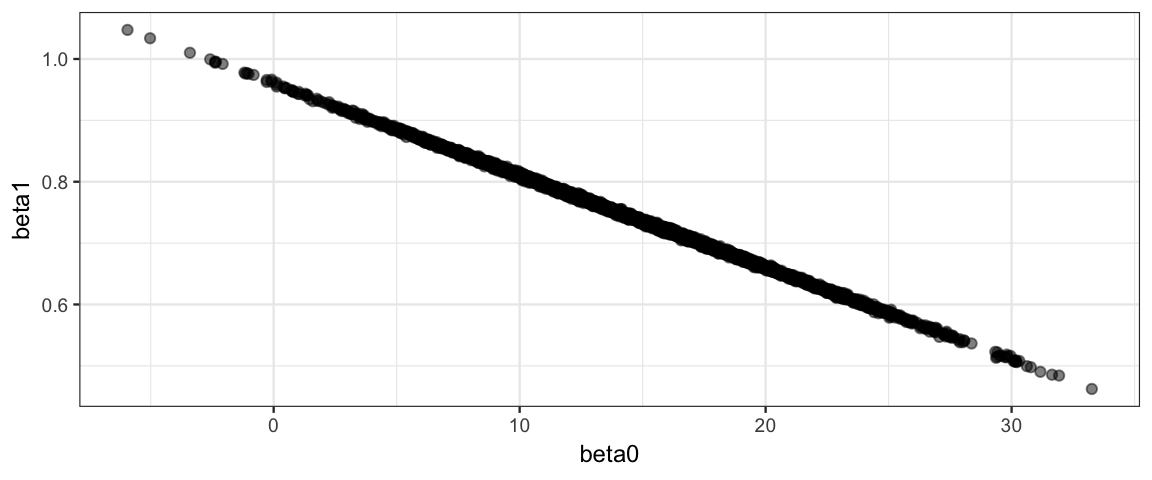
mcmc_combo(as.mcmc.list(galton_stanfit),
pars = c("beta0", "beta1", "sigma", "nu"))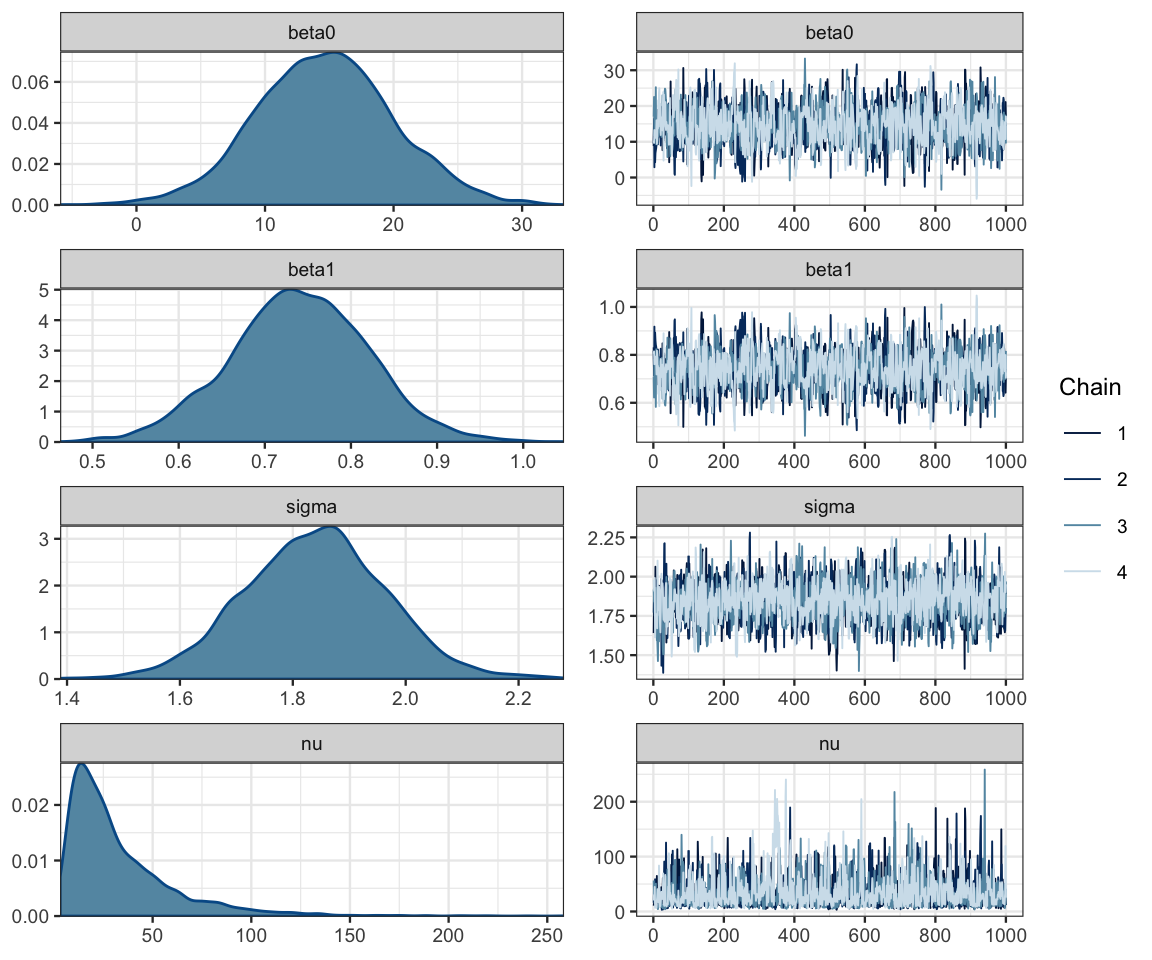
17.6 Two Intercepts model
In the example above we have been dealing with the women alone, but we can build a model that handles men and women at the same time. One such model is the “mutliple intercpets” model. In this model, both groups (men and women) will have the same slope, but the intercepts are allowed to differ.
Note: Because the distribution of nu is skewed, we are computing \(log_{10}(\nu)\) in this model. \(\log_{10}(30) \approx 1.5\).
data {
int<lower=0> N; // N is a non-negative integer
vector[N] y; // y is a length-N vector of reals
vector[N] x; // x is a length-N vector of reals
int<lower=0> g[N]; // g is a length-N vector of integers (for groups)
}
parameters {
real beta0;
real beta1;
real beta2;
real<lower=0> sigma;
real<lower=0> nuMinusOne;
}
transformed parameters{
real<lower=0> log10nu;
real<lower=0> nu;
nu = nuMinusOne + 1;
log10nu = log10(nu);
}
model {
for (i in 1:N) {
y[i] ~ student_t(nu, beta0 + beta1 * x[i] + beta2 * g[i], sigma);
}
beta0 ~ normal(0, 100);
beta1 ~ normal(0, 4);
beta2 ~ normal(0, 4);
sigma ~ uniform(6.0 / 100.0, 6.0 * 100.0);
nuMinusOne ~ exponential(1/29.0);
}library(rstan)
set.seed(12345)
GaltonBoth <- mosaicData::Galton %>%
mutate(midparent = (father + mother)/2,
group = as.numeric(factor(sex)) - 1) %>% # 0s and 1s
group_by(family) %>%
sample_n(1)
galton2_stanfit <-
sampling(
galton2_stan,
data = list(
N = nrow(GaltonBoth),
x = GaltonBoth$midparent,
y = GaltonBoth$height,
g = GaltonBoth$group # 0s and 1s
),
chains = 4,
iter = 2000,
warmup = 1000
) galton2_stanfit## Inference for Stan model: 867602e844da9001ddd6fca37724a70c.
## 4 chains, each with iter=2000; warmup=1000; thin=1;
## post-warmup draws per chain=1000, total post-warmup draws=4000.
##
## mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
## beta0 23.72 0.15 5.83 12.07 20.03 23.72 27.65 35.03 1441 1
## beta1 0.60 0.00 0.09 0.44 0.55 0.60 0.66 0.78 1447 1
## beta2 5.23 0.01 0.32 4.59 5.02 5.24 5.46 5.84 2289 1
## sigma 2.09 0.00 0.13 1.84 2.00 2.09 2.18 2.34 2240 1
## nuMinusOne 36.01 0.57 27.62 6.79 16.18 28.16 47.52 107.40 2352 1
## log10nu 1.46 0.01 0.31 0.89 1.24 1.46 1.69 2.04 2141 1
## nu 37.01 0.57 27.62 7.79 17.18 29.16 48.52 108.40 2352 1
## lp__ -317.92 0.04 1.59 -321.86 -318.77 -317.57 -316.76 -315.82 1470 1
##
## Samples were drawn using NUTS(diag_e) at Sat Apr 13 13:42:54 2019.
## For each parameter, n_eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor on split chains (at
## convergence, Rhat=1).galton2_mcmc <- as.mcmc.list(galton2_stanfit)
Post_galton2 <- posterior(galton2_stanfit)
mcmc_combo(galton2_mcmc, regex_pars = c("beta", "sigma", "log10nu"))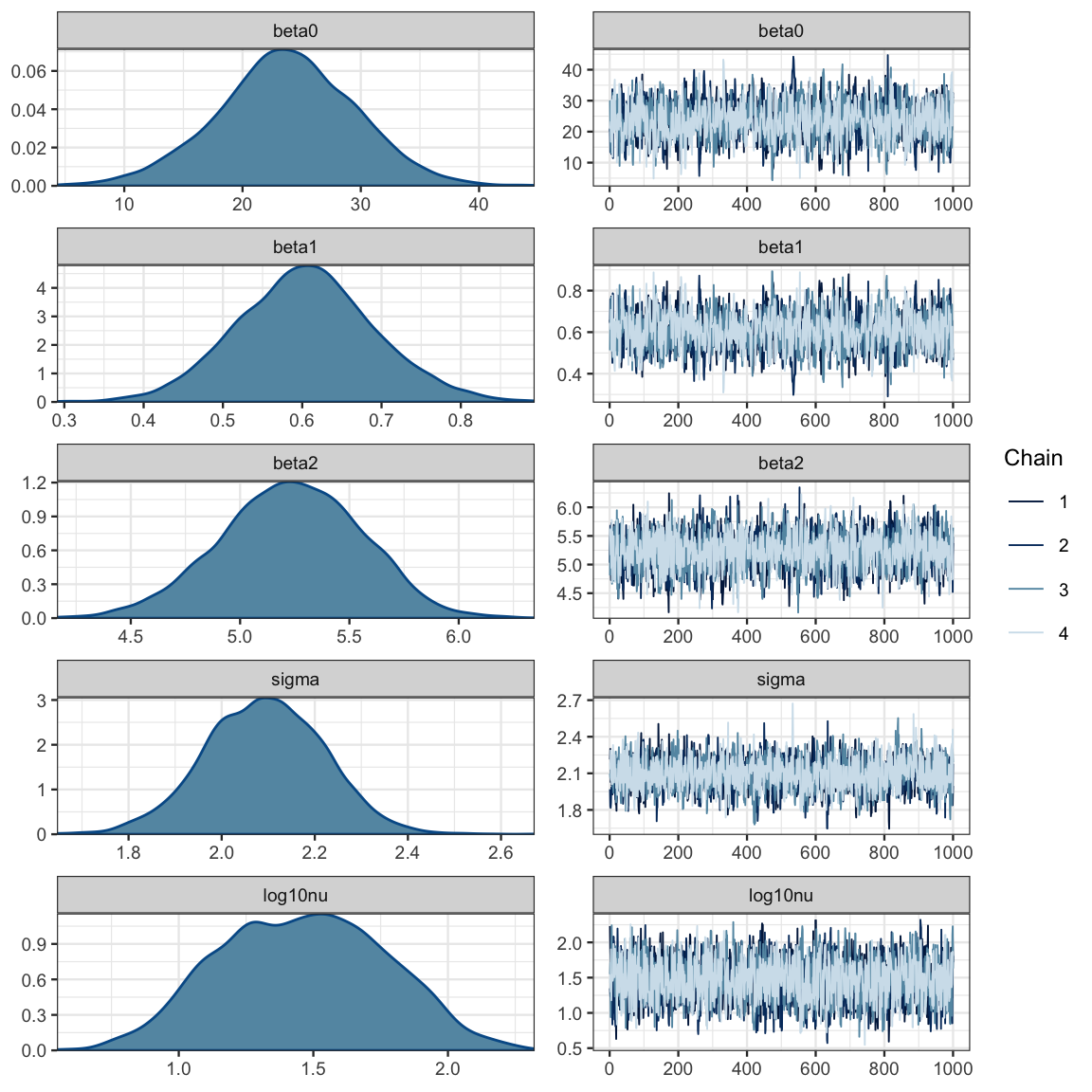
plot_post(Post_galton2$beta2, xlab = "beta2", hdi_prob = 0.95)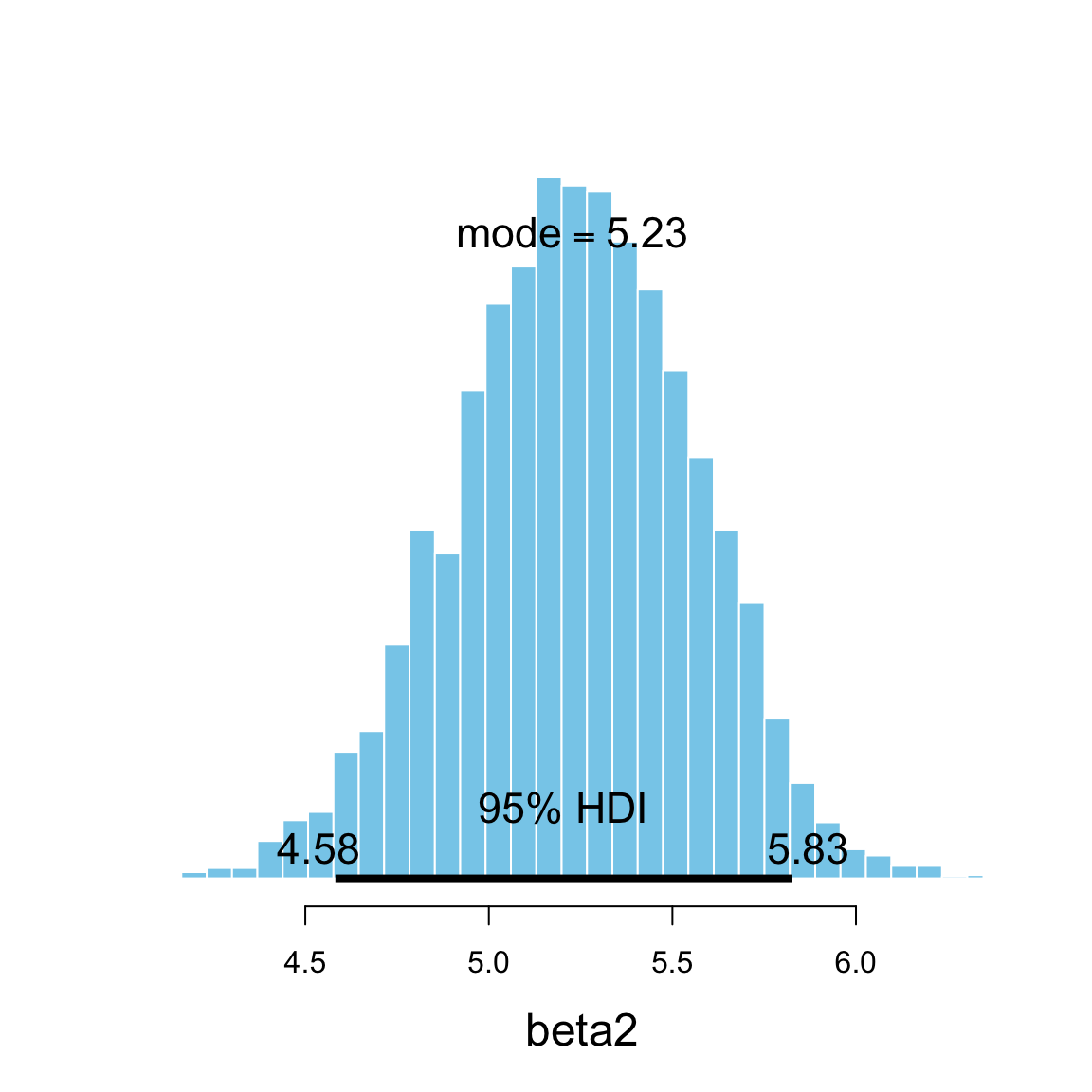
## $posterior
## ESS mean median mode
## var1 2342 5.234 5.238 5.228
##
## $hdi
## prob lo hi
## 1 0.95 4.582 5.825mcmc_pairs(galton2_mcmc, regex_pars = "beta", off_diag_fun = "hex")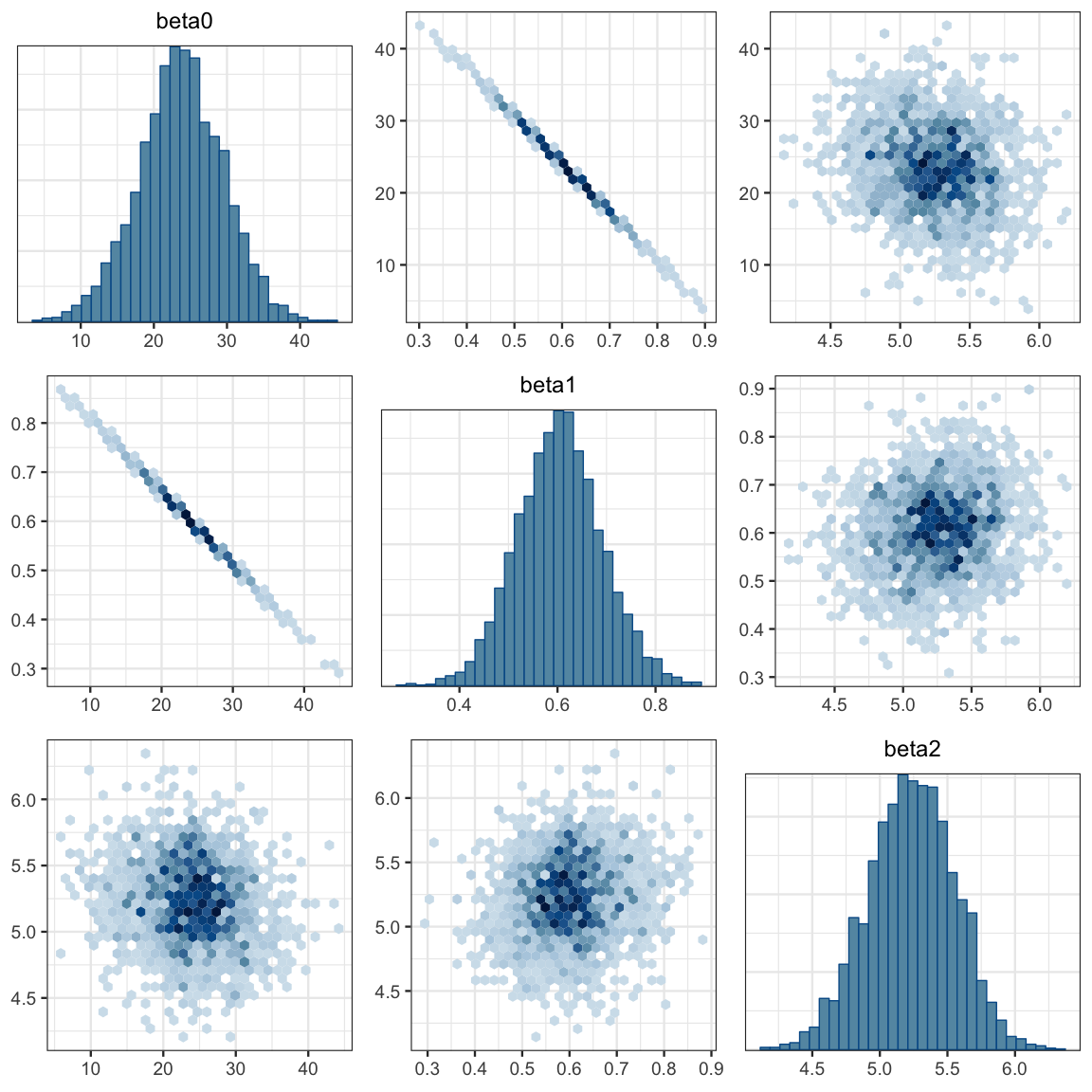
mcmc_areas(galton2_mcmc, regex_pars = "beta2", prob = 0.95)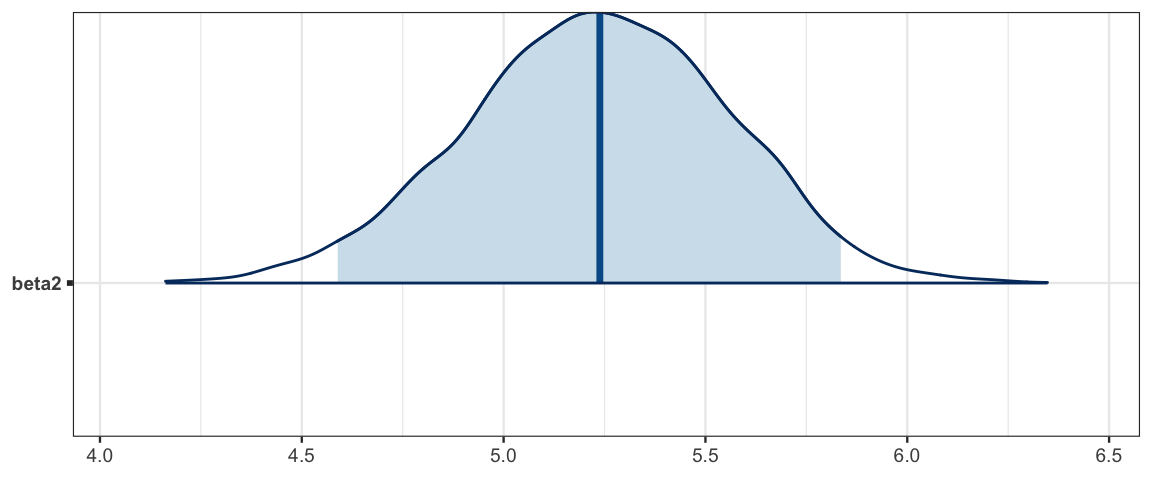
mcmc_areas(galton2_mcmc, regex_pars = "log10nu", prob = 0.95)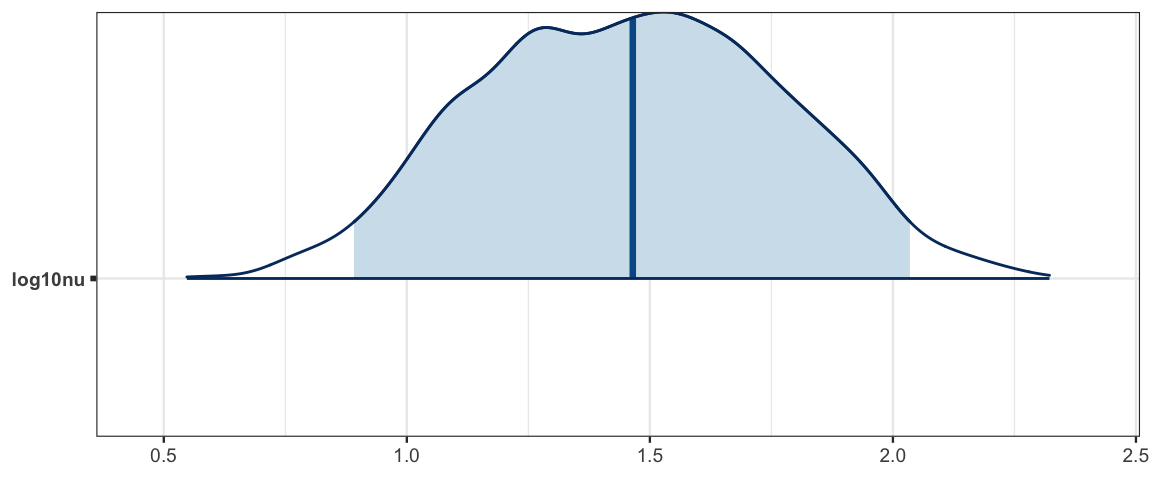
head(GaltonBoth, 3) ## # A tibble: 3 x 8
## # Groups: family [3]
## family father mother sex height nkids midparent group
## <fct> <dbl> <dbl> <fct> <dbl> <int> <dbl> <dbl>
## 1 1 78.5 67 F 69 4 72.8 0
## 2 10 74 65.5 F 65.5 1 69.8 0
## 3 100 69 66 M 70 3 67.5 1yind <-
posterior_calc(
galton2_stanfit,
yind ~ beta0 + beta1 * midparent + beta2 * group +
rt(nrow(GaltonBoth), df = nu) * sigma,
data = GaltonBoth
)
ppc_intervals_grouped(
GaltonBoth$height, yind, group = GaltonBoth$sex,
x = GaltonBoth$midparent) 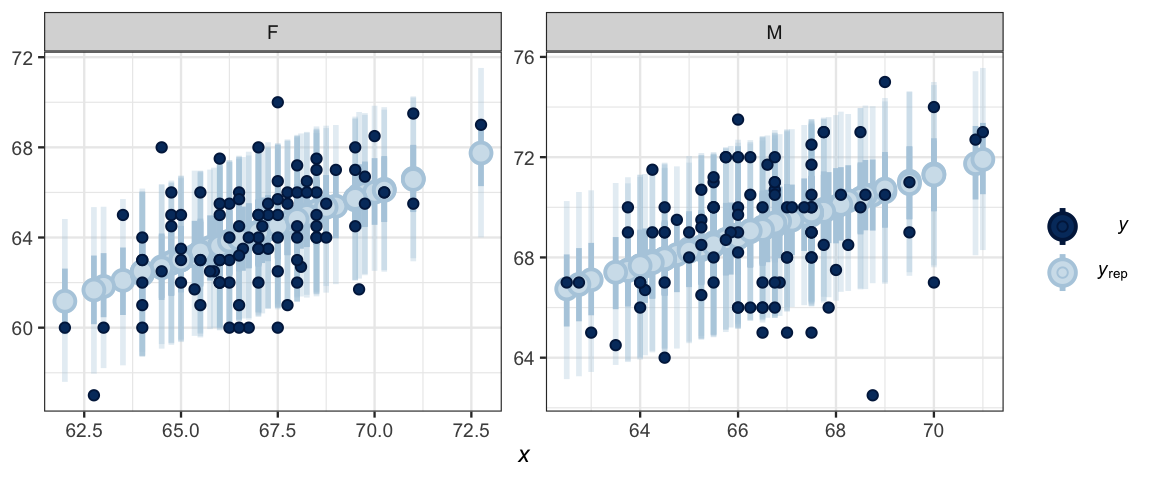
ppc_data <-
ppc_intervals_data(
GaltonBoth$height, yind, group = GaltonBoth$sex,
x = GaltonBoth$midparent)
glimpse(ppc_data)## Observations: 197
## Variables: 11
## $ y_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22…
## $ y_obs <dbl> 69.0, 65.5, 70.0, 66.0, 68.0, 73.0, 67.5, 66.0, 65.5, 64.0, 70.0, 68.0, 66.0,…
## $ group <fct> F, F, M, M, M, M, M, F, F, F, M, M, F, M, F, M, M, M, M, F, M, M, F, F, F, M,…
## $ x <dbl> 72.75, 69.75, 67.50, 67.85, 67.50, 67.75, 68.00, 67.75, 67.75, 67.50, 67.00, …
## $ outer_width <dbl> 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.9, 0.…
## $ inner_width <dbl> 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.…
## $ ll <dbl> 64.00, 62.39, 66.05, 66.41, 66.09, 66.26, 66.27, 61.05, 61.01, 61.05, 65.83, …
## $ l <dbl> 66.28, 64.49, 68.36, 68.57, 68.32, 68.46, 68.56, 63.21, 63.23, 63.23, 68.01, …
## $ m <dbl> 67.75, 65.89, 69.83, 69.95, 69.76, 69.92, 70.02, 64.67, 64.66, 64.63, 69.47, …
## $ h <dbl> 69.22, 67.32, 71.24, 71.40, 71.09, 71.43, 71.56, 66.16, 66.08, 66.01, 70.92, …
## $ hh <dbl> 71.52, 69.44, 73.52, 73.60, 73.27, 73.54, 73.68, 68.35, 68.31, 68.16, 73.12, …gf_ribbon(ll + hh ~ x, fill = ~ group, data = ppc_data) %>%
gf_ribbon(l + h ~ x, fill = ~ group, data = ppc_data) %>%
gf_point(y_obs ~ x, color = ~ group, data = ppc_data) %>%
gf_facet_grid(group ~ .)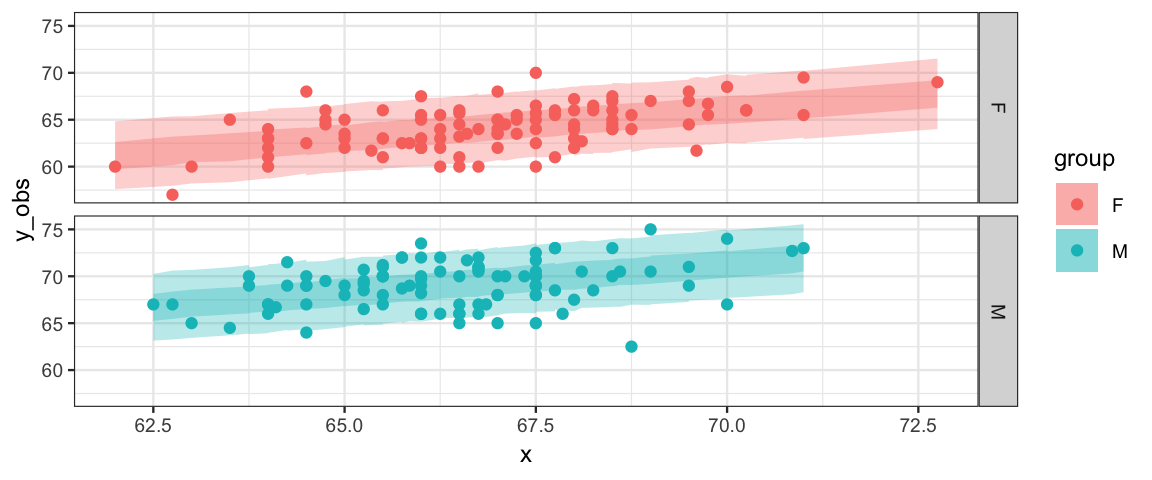
So what do we learn from all of the ouput above?
- Diagnostics suggest that the model is converging appropriately.
- Posterior predicitive checks don’t show any major disagreements between the model and the data. (So our restriction that the slopes of the lines be the same for men and women seems OK.)
- The “noise distribution” seems well approximated with a normal distribution (The majoritiy of the posterior distibution for \(\log_{10}(\nu)\) is above 1.5.)
hdi(posterior(galton2_stanfit), regex_pars = "nu", prob = 0.90)| par | lo | hi | mode | prob |
|---|---|---|---|---|
| nuMinusOne | 4.1442 | 73.403 | 11.744 | 0.9 |
| log10nu | 0.9737 | 1.958 | 1.566 | 0.9 |
| nu | 5.1442 | 74.403 | 12.744 | 0.9 |
* *Note: HDIs are not transformation invariant because typically the
transformation alterns the shape of the posterior.*- The new feature of this model is \(\beta_2\), which quantifies the difference in average heights of men and women whose parents have the same heights. Here’s the 95% HPDI for \(\beta_2\) (along with the slope and intercept):
hdi(posterior(galton2_stanfit), regex_pars = "beta")| par | lo | hi | mode | prob |
|---|---|---|---|---|
| beta0 | 12.5363 | 35.456 | 22.1604 | 0.95 |
| beta1 | 0.4333 | 0.774 | 0.5954 | 0.95 |
| beta2 | 4.5819 | 5.825 | 5.1697 | 0.95 |
We could let other things differ accross groups as well: slopes, sigmas, nu, etc.
17.7 Exercises
Use Galton’s data on the men to estimate
- The average of height of men whose parents are 65 and 72 inches tall.
- The middle 50% of heights of men whose parents are 65 and 72 inches tall.
You may use either JAGS or Stan.
When centering, why did we center x but not y?